

S3 Replication is a key feature for teams who need to asynchronously duplicate existing objects and their metadata across Amazon Web Services (AWS) S3 buckets. But while useful, S3 Replication often doesn’t work or takes too long due to:
- Bucket versioning.
- Permission and ownership misconfigurations.
- The size and number of objects, and other issues.
Many factors can cause regular or sporadic replication failures, making the debugging process frustrating and time-consuming. Plus, failures get even more complicated as you try to replicate data across multiple regions, accounts, or AWS services.
In this article, we help you understand the different issues that can lead to replication failures. We also discuss the standard replication delays that can occur when replicating large objects across different regions.
But before we dive in, it’s worth noting that S3 Replication (and AWS replication in general) has some fundamental issues that can’t be avoided. Mainly, it can be slow, expensive, and difficult to debug, especially when replicating across regions or services.
That’s why, in the second part of this article, we show you how Resilio Platform can help you avoid these issues with faster, simpler, and more reliable replication.
Resilio Platform is our agent-based replication solution that:
- Offers industry-leading replication speed thanks to its P2P replication topology and proprietary WAN transfer technology.
- Can be deployed on your existing infrastructure and start replicating in as little as two hours, thanks to its easy setup.
- Lets you replicate data quickly and efficiently across any cloud provider (AWS, GCP, Azure, etc.), on-prem, or in a hybrid cloud environment.
To learn how Resilio Platform can help your company replicate in a fast, reliable, and cost-efficient way, schedule a demo with our team.
Common Amazon S3 Replication Issues, Failure Reasons, and Other Factors to Consider
Whenever you get a “FAILED” replication status, your first order of business should be to check the “failureReason” event to see the exact cause (you can receive S3 Event Notifications via Amazon SQS, SNS, or AWS Lambda).
The full list of S3 Replication reasons can be found here.
As you can see, there are nearly 30 reasons that may pop up. Below we discuss the most common ones, starting with permission and ownership issues.
Note: We’re exploring reasons that lead to the “FAILED” replication status, which is the terminal state that occurs due to misconfiguration. The “PENDING” status isn’t a focus of this article, so it will only be discussed briefly at the end of this section.
Permissions and Ownership
First, start troubleshooting by checking if the Amazon Resource Name (ARN) of the destination bucket is correct and that the status of the replication rule is set to “Enabled”.
You can do this by opening the source bucket’s replication configuration. This may give you an easy fix to your issue, without having to dive into complex configuration settings.
If that’s not the issue, you want to dive deeper into the different types of permissions for your buckets, alongside their public access and bucket ownership settings.
Here are some specific things to look out for:
- Minimum role permissions. By default, all S3 objects are private, so S3 needs permissions to replicate objects from a source bucket. These can be given via AWS Identity Access Management (IAM) roles. AWS has detailed tutorials on how to create IAM roles for buckets in the same or different accounts, which you can check out if you haven’t worked with IAM before. Also, if you’re trying to replicate across accounts, check whether the destination bucket’s IAM policy grants sufficient permissions to the replication role.
- KMS permissions. If you’re using AWS Key Management Service (KMS) to encrypt source objects in a bucket, the replication rule must be changed to include those objects. This can be done by opening the source bucket, going to “Management”, selecting the replication rule, clicking on “Edit”, and selecting “Replicating objects encrypted with AWS KMS” (under the “Encryption” tab). From here, you just need to select a KMS key. Note: When the destination bucket is in another AWS account, you also have to specify a KMS key that’s owned by that account. If you’re working with KMS, refer to the AWS documentation on key states.
- ACLs (access control lists). If the source or destination bucket is using ACLs, your replication will fail if the latter bucket is blocking public access while the former allows public access. Additionally, if the objects in the source bucket were uploaded by another account, the source account might not have permissions for them, resulting in a replication failure. In that case, when the source bucket has active ACLs, check to see if object ownership is set to “Object owner preferred” or “Bucket owner preferred”. The process of configuring and managing ACLs is described in this AWS article.
- Additional permissions for changing replica owners. By default, the owner of the original object also owns the replicated objects. If you want to change that, you have to include the IAM role “s3:ObjectOwnerOverrideToBucketOwner” permission. This permission must be granted to the source bucket owner via the destination bucket policy whenever the two buckets are owned by different accounts. You can check out the AWS documentation on the owner override setting for more details.
Versioning
AWS S3 buckets have a versioning subresource associated with them. By default, buckets are unversioned, so this subresource stores an empty configuration.
However, for S3 Replication to work, both the source and destination buckets must have versioning enabled. To enable versioning, you need to send a request to S3 with a versioning configuration that includes the “Enabled” status, like so:
<VersioningConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/"> <Status>Enabled</Status> </VersioningConfiguration>Again, make sure to double check the bucket name before doing this. If you’re not the bucket owner, you’ll need to ask the owner to either enable versioning or give you permission to do so.
For more details and examples on how to enable versioning using the console, REST API, SDKs, and Command Line Interface (AWS CLI), check out this article.
Note: While versioning is typically employed when you want to keep multiple variants of an object in the same bucket, it’s also necessary for the replication process. The reasons for this mostly have to do with the proper deletion of objects. If you’re interested, refer to this AWS forum thread on why versioning is necessary.
Cross-Region Replication and Replication Latency
In some cases, you may want to replicate objects across buckets located in different regions — a process called cross-region replication (CRR). This can be essential for meeting compliance requirements, minimizing latency, and implementing a disaster recovery strategy.
In these cases, S3 can replicate most objects within 15 minutes. However, cross-region replication can sometimes take hours depending on the size and number of objects being replicated. During this time, objects will have the “PENDING” status until their eventual replication (or failure if something goes wrong).
You can monitor cross-region replication, including key metrics like the maximum replication time to the destination bucket, using S3 Replication Time Control (RTC).
However, there’s no way to guarantee fast replication for all objects when replicating large objects across many regions, which is one of the key issues with S3 Replication, as we’ve discussed in our article on S3 Replication latency.
The Fundamental Problems with S3 Replication
Despite its versatility and usefulness, S3 Replication has some downsides that can’t be avoided. Specifically:
- It can be slow and unpredictable. While most objects should replicate within 15 minutes, sometimes replication can take up to a few hours depending on the size and number of objects. This unpredictability can cause lots of headaches for companies that rely on their data being constantly up-to-date in regions across the globe.
- It’s difficult and time-consuming to debug. As we showed, there are lots of issues that can cause replication failures (plus nearly 30 concrete failure reasons you may run into when receiving the “failureReason” event). As you expand to complex use cases like CRR or cross-account replication, it gets even more difficult to pinpoint the exact problems causing replication failures.
- It’s limited to the AWS service ecosystem. Like all other cloud providers, AWS aims to keep users within its ecosystem. As a result, you can’t use S3 Replication (or another one of AWS’ replication tools) to easily move data into another cloud like Azure or GCP.
- It can get expensive. S3 storage prices may be cheap depending on your S3 storage class and lifecycle configuration but data transfer and replication costs can quickly add up. AWS’ sheer complexity means that mitigating this problem can be difficult because you need to consider lots of moving parts, like the costs associated with cross-region replication, S3 Replication Time Control, S3 Batch Replication, and potentially other AWS services. Note: AWS doesn’t charge for transferring data between S3 buckets in the same region, so this may not be an issue if you don’t replicate across other regions, AWS services, or other cloud providers.
How to Simplify, Speed Up, and Secure the Replication Process with Resilio Connect
Resilio Platform is a real-time replication software that uses P2P file transfer and proprietary WAN acceleration technology to deliver the fastest replication speeds in the industry (10+ Gbps).
Brands like Blockhead, Skywalker Sound, and Turner Sports use our software to:
- Achieve near-instant replication speeds.
- Transfer objects over LAN or WAN networks.
- Set up, manage, and debug the replication process in an easy, cost-efficient way.
- Handle massive data workloads, including replicating to many endpoints and transferring large (or many) objects.
You can also use Resilio to bring data into AWS and quickly replicate it across regions, other AWS services, and even other cloud providers. In the next section, we discuss exactly how Resilio Platform works and six of its main benefits over S3 Replication.
#1 Fast Replication Speed and High Availability
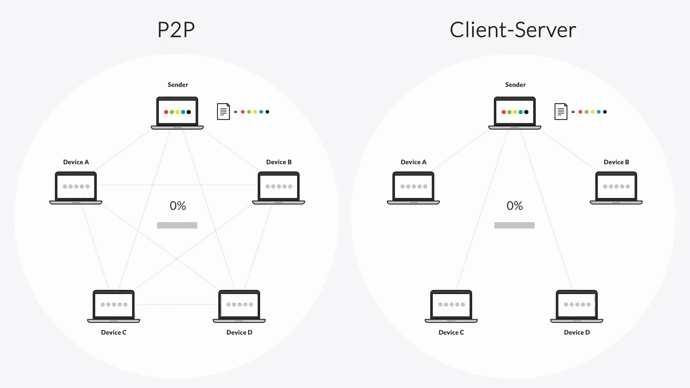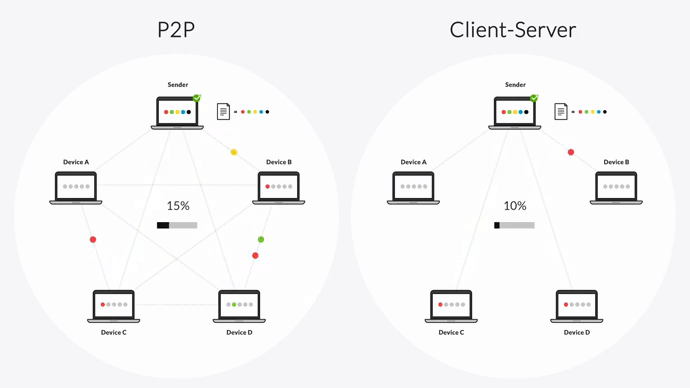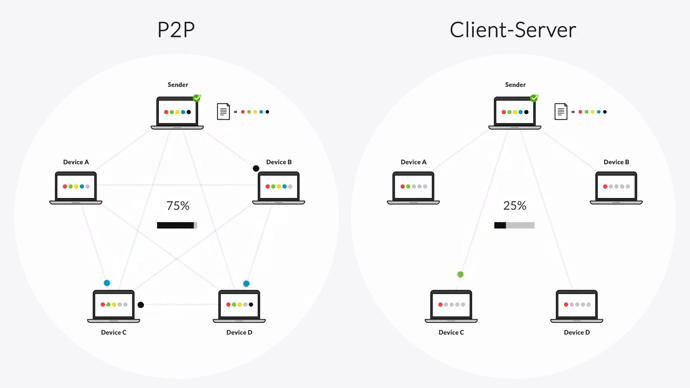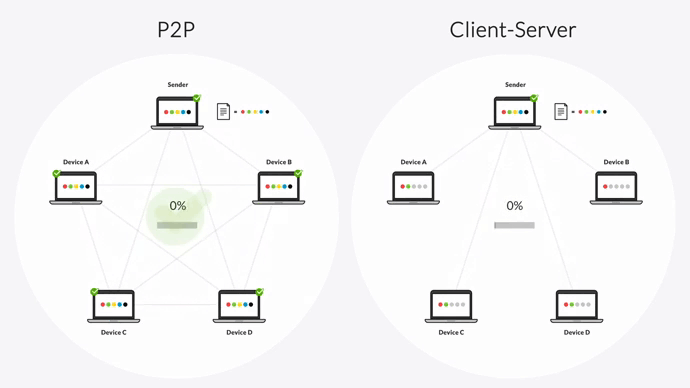
Most replication solutions use standard point-to-point replication topologies. These usually come in one of two flavors:
- Client-server replication, where one server is designated as a hub and the others are designated as clients. The hub can replicate data to any client, while clients are limited to only sharing data with the hub. This means clients can’t replicate data between each other, making the process overly reliant on the hub.
- “Follow-the-sun” replication, where replication occurs from one server to the other sequentially — Server 1 syncs with Server 2, after which Server 2 syncs with Server 3, and so on.
In both of these models, replication takes a long time because it only occurs between a single server and another (hence the name “point-to-point”). As more endpoints are added and the volume of data grows, delays can get much worse.
In addition, most replication solutions use standard file transfer protocols like TCP/IP. While these are fine for some cases, they’re not optimized for WANs (wide area networks) because they treat packet loss as a network congestion problem and reduce the transfer speed. On a WAN, packet loss doesn’t occur due to network congestion, so lowering transfer speeds just increases replication latency unnecessarily.
That’s why Resilio Platform uses a unique P2P (peer-to-peer) replication method and a proprietary WAN acceleration technology.
First, P2P replication lets all servers share data with each other. In other words, every server functions as a hub. If one server goes down, Resilio can still replicate or retrieve objects from the nearest available device by automatically routing around the outage. Besides being faster, this also makes Resilio ideal hot-site disaster recovery software.
Resilio also splits files into separate pieces that can be transferred independently of each other — a process called file chunking, which lets objects be replicated across your environment simultaneously.
This combination of P2P replication and chucking lets every server replicate data at the same time, resulting in 3-10x faster replication speeds than traditional point-to-point solutions.
Plus, the P2P architecture also makes Resilio Platform an organically scalable replication solution.
The more servers you add, the better Resilio will perform, which is a massive benefit over traditional replication tools that take longer to replicate your data as the number of replication endpoints increases. For example, Resilio can synchronize data 50% faster than point-to-point solutions in a 1:2 scenario and 500% faster in a 1:10 scenario.
Second, Resilio Platform also uses a proprietary transfer protocol Zero Gravity Transport™ (ZGT). ZGT was designed to optimize transfers over WANs by using a congestion control algorithm that calculates the ideal send rate.
ZGT also:
- Creates a uniform packet distribution over time to avoid network overload.
- Sends packet acknowledgements for a group of packets, as opposed to each individual packet.
- Reduces unnecessary retransmissions by retransmitting lost packets once per Round Trip Time.

Overall, the combination of P2P transfer and WAN optimization makes Resilio a much faster, more reliable, and more predictable replication solution than S3 Replication.
#2 Simpler Replication with High Visibility and Centralized Management
AWS offers different ways to replicate your data — from the standard S3 Replication to AWS DataSync, S3 CopyObjects API, and S3 Batch Operations Copy.
Each has its own pros and cons and is suitable for different use cases. For example, S3 Replication has limitations when it comes to retroactive replication and replicating only the current version of objections.
While this mix provides lots of flexibility, it also massively increases complexity because you have to learn each service, understand its use cases, and get used to how it works.
In contrast, Resilio Platform lets you set up, control, and monitor the entire replication process with a single tool, instead of using three or four replication services.
You can easily control how replication occurs in your environment through our dashboard.
For example, you can create different schedules for different replication jobs, set bandwidth usage limits, set up notification events, adjust buffer size, packet size, and much more. This is a great way to ensure your replication is as efficient as possible.

Our Central Management Console also gives you a detailed view of:
- Object replications, synchronizations, and transfer jobs.
- Real-time transfer performance metrics.
- Individual endpoints.
- The history of all executed jobs.
- Complete audit trail and event longs.
Lastly, Resilio Platform lets you expose all your objects as files and folders, which are more familiar and intuitive to work with.
#3 Service, Region, and Cloud Flexibility
Unlike S3 Replication (or AWS’ other replication solutions), Resilio Platform is a cloud-agnostic software that builds on open standards, open file formats, and a multi-cloud architecture.
As a result, you have full flexibility to:
- Use any type of storage, including file, block, or object storage.
- Ingest data into AWS and replicate it across any AWS service or region. For example, you can replicate data across North American and EU S3 buckets or across services like Amazon EFS or FSx. Again, you don’t have to worry about switching between S3 Replication, DataSync, or any other replication service when doing this.
- Replicate objects across your on-prem environment and even into other clouds. This means you can use a single interface to manage the replication process across multiple cloud providers, like AWS, Azure, GCP, Wasabi, Backblaze, or any other S3-compatible object storage.
Put simply, you’re not limited when it comes to where you store and replicate your data.
#4 Efficiency
Resilio’s P2P architecture, which we discussed earlier, means that every server in your environment takes part in the replication process at the same time.
This makes replication much more efficient because you can quickly sync objects in any direction — one-to-one, two-way, one-to-many, many-to-one, and N-way — to replicate data across AWS regions and services.
Our engineering team is also constantly working to improve Resilio’s energy consumption and cost efficiency. In one of our recent updates, we reduced the average memory footprint required on replication jobs by 80%. Plus, we optimized time, merging, CPU usage, indexing, storage io, and end-to-end transport.
Lastly, with Resilio Connect, you can also store frequently accessed data locally. That way, you don’t have to download data from the AWS cloud every time you need it, which can drastically lower your egress costs.
Note: We’ve explored this benefit in more detail in our article on the best AWS File Gateway alternative.
#5 Ease of Setup and Use
Resilio Platform is also a software-only solution, meaning it can be installed on your existing infrastructure, without the need to change your proprietary hardware or buy new machines.
This helps your organization save time and money by giving your team the flexibility to continue using their existing tools. The simple setup also lets you deploy Resilio Platform on your infrastructure and start replicating in as little as 2 hours.
Resilio Platform also supports and can run on:
- VMware, Citrix, and other virtual machines.
- All popular operating systems, like Linux, Microsoft Windows, Mac, and Android.
- Industry-standard servers, laptops, desktops, and mobile devices (we have apps for both Android and iOS).
- DAS, SAN, and NAS (including OSNexus, Synology, TrueNAS, QNAP, and more) storage. Again, this means you don’t need to spend time and money on purchasing new hardware and training your team on it.
#6 State-of-the-Art Security
Security is among the biggest concerns when it comes to storing and moving data, whether on-prem or in the cloud. That’s why we’ve built advanced security and data integrity features for Resilio Connect, including:
- AES 256 encryption, which encrypts your data at rest and in transit.
- Mutually authenticated endpoints, which must be pre-approved in order to receive data.
- Cryptographic data integrity validation, which ensures files always arrive uncorrupted and intact.
- Access management, which means you can set granular permissions that govern who can access your data.
- Data immutability, which means Resilio stores immutable copies of data in the public cloud, protecting you from ransomware and data loss.
Get Faster, Reliable, and Predictable Replication with Resilio Connect
Resilio Platform can help you achieve superior replication speeds thanks to its organically scalable P2P topology and efficient WAN optimization technology.
Our software is also:
- Easy to set up and manage.
- Highly secure, thanks to AES 256 encryption.
- Flexible in terms of replicating across AWS regions, services, on-prem environments, and other cloud providers.
For more details on how Resilio Platform can provide your organization with fast, reliable, efficient, and secure object replication, schedule a demo with our team.




