

Is your DFSR backlog not clearing? Are your files sitting in a “scheduled” state without replicating or syncing?
A growing backlog queue is the number one problem we hear from DFSR users. And because there are no good DFSR monitoring tools, diagnosing and fixing these issues is an endless source of headaches and frustration. To help ease your troubles, we’ve put together this article that covers:
- How to gain insight into your DFS replication environment to more easily find, diagnose, and fix the problem
- The 7 most common solutions to growing DFSR backlog queues
- 3 Reasons your DFSR issues will persist and how Resilio Platform (our DFSR alternative) overcomes those challenges to provide reliable, resilient replication
Resilio Active Everywhere (formerly Resilio Connect) is a worry-free file replication solution that provides faster, more reliable transfer using a P2P transfer architecture, WAN optimization, and more. If you want to try replicating files with Resilio, you can get set up and begin replicating your Windows file servers in as little as 2 hours by scheduling a demo with our team.
Start by Gaining Insight into the State of DFS Replication
When diagnosing problems with DFSR, the first step is to gain insight into your replication environment and narrow down potential causes of error and avoid wasting time trying erroneous solutions.
Unfortunately, DFSR provides little visibility into the state of your replication network. But the following methods should give you some information you can use to understand why your backlog isn’t clearing:
Use DFS Command Lines
1) Get-DfsrState
Use the command line “Get-DfsrState” to check the current replication state of your DFS replication group partners.
2) Get-DfsrBacklog
Use the command line “Get-DfsrBacklog” to see pending updates between two Windows-based file servers that are part of your dfs replication service.
3.) Use the dfsrdiag.exe tool
To check DFS replication backlog status, install the dfsrdiag.exe tool by running one of the following commands from Powershell:
“Install-WindowsFeature RSAT-DFS-Mgmt-Con”
"DFSDiag /TestDFSIntegrity /DFSRoot: /Full."
"dfsrdiag backlog /rgname:'Group Name' /rfname:'folder name' /smem:servername /rmem:servername"
Check Your Active Directory
Use the following commands to check the connectivity in your Active Directory:
Command: $ DFSRDIAG dumpadcfg /member:SERVERNAME
This yields any information that Active Directory has about DFS, the replication groups, and the folders it belongs to.
Command: $ DFSRDIAG pollad /member:SERVERNAME
This makes the server check in with Active Directory. It should result in “operation succeed.”
Command: $ FDSRDIAG replicationstate
This shows you what’s currently replicating.
Run a diagnostic Report
To run a diagnostic report, start DFS Management, expand replication, then:
- Right-click on the replication group for the namespace.
- Click “Create Diagnostic Report.”
Try These 7 Common Solutions for Clearing Your DFSR Backlog
Solution 1: Check Network Cards and Antivirus Software
Before exploring other options, start by checking and eliminating the simplest potential causes of replication failure. This includes:
- Network interface cards: Update your server’s network interface drivers to the latest version.
- Antivirus software: Your antivirus software could potentially block replication. Try disabling your antivirus software and restarting replication to see if this is the issue. If so, be sure that your antivirus software is aware of replication and set any necessary exclusions.
Solution 2: Delete & Recreate the Replication Group
A common quick fix involves deleting and recreating the replication group:
- Point all the users in your network to a single server.
- Backup the shares and delete the replication group.
- Refresh the configuration for each server from the Active Directory.
- Stop replication on all replication group partners.
- Backup the configuration folder from the SYSVOL.
- Create a new replication group on your primary server.
- Start the DFS replication group and allow synchronization.
- Restore the links to the other partners once the sync is complete.
Solution 3: Close Files before Syncing
DFSR can not sync files that are in use. So any files that are open won’t replicate. Try closing files and restarting replication.
Solution 4: Check Staging Area Quota
The staging area in DFSR is used to:
- Isolate the files from the changes on the file system.
- Reduce the cost of compression and computing RDC hashes across multiple partners.
The default staging area quota for DFSR is 4 GB. But your staging quota must be, at a minimum, as large as the 32 largest files in the replicated folder. This is particularly true for initial replication, as it will make much more use of the staging area than day-to-day replication.
To find the 32 largest files and calculate the staging area, use the following commands:
1) Get-ChildItem c:\\temp -recurse | Sort-Object length -descending | select-object -first 32 | ft name,length -wrap –auto
This command will provide the file names and the sizes of the files (in bytes). Use it to identify the 32 largest files. Add them up to identify your minimum staging area quota.
2) Get-ChildItem c:\\temp -recurse | Sort-Object length -descending | select-object -first 32 | measure-object -property length –sum
This command will provide the size (in bytes) of the 32 largest files in a folder. Again, add them up to identify your minimum staging area quota. Then set your staging quota to this number.
These commands will help you find the minimum staging area quota. But when it comes to setting your staging area quota, bigger is better (up to the total size of the replicated folder).
Solution 5: Prevent High Backlog by Staggering Replication Folder Rollouts
A high DFSR backlog can lead to problems that increase the backlog even more.
For example, if your DFS backlog has been growing for multiple weeks, you may have multiple versions of the same files waiting to be replicated. This can lead to conflict resolution errors where older versions of files win and outdated data is replicated.
This issue often occurs when admins roll out too many new replication folders at once, which can overload your hub server. To prevent this from happening, stagger rollouts so that initial replication is finished within a reasonable time frame.
Solution 6: Balance the Load on Hub Servers
Since DFSR operates on a client-server architecture, the hub server(s) is critical to its operation. Many replication environments are deployed with just a single hub server that must service many branch office servers. The hub server becomes overwhelmed and can’t perform all the tasks required of it, so file replication backs up.
When using DFSR with multiple branch office servers, you should have at least two hub servers. Not only does this protect you in the event that one hub server goes down, it also balances the load between servers and prevents replication delays.

Since every environment is unique, you’ll need to determine how many branch office servers a single hub server can service by monitoring your backlogs. To learn more about deploying hub servers, check out this Microsoft article on tuning replication performance.
Solution 7: Don’t Stop DFSR for Too Long
You may need to temporarily stop DFS replication on a particular replication group for one reason or another. In this event, be sure you:
- Properly stop replication by setting the schedule to no replication for the specific replication group.
- Don’t stop replication for too long.
DFSR must be running in order to read updates to the USN Journal. If lots of files are changed, added, or deleted while DFSR is stopped, it can cause journal wrap to occur.
A journal wrap occurs when the change journal cannot store all entries and must overwrite old journal entries. In a large environment with lots of files or large files, it can take DFSR a long time to recover from journal wrap. During this time, replication can be very slow or not occur at all. Backlogs will build up during this process.
3 Reasons Why DFSR Issues Will Persist & How Resilio Overcomes Those Challenges
Ultimately, you’ll have to confront the major issue with DFSR: it’s an unreliable replication tool that’s prone to errors. As your needs and replication environment grow, your DFSR replication issues will get worse. And if you…
- Are tired of wasting time addressing support tickets and putting out fires,
- Want certainty that your files are where they need to be in a reliable state, and
- Want a replication tool that doesn’t hinder business productivity,
… Then you’ll need to find an alternate file replication solution.
Here’s a list of the 5 fundamental reasons DFSR issues persist and how Resilio overcomes those challenges.
1. DFSR Performs Poorly over High-Latency, Long-Distance WANs (Wide Area Networks)
Transferring files over long distance WAN networks significantly increases the travel time and potential for packet loss. DFSR performs poorly over WAN networks because:
- It uses a client-server transfer architecture.
- It uses TCP/IP transfer protocol.
- It lacks WAN optimization technology — i.e., technology for optimizing the way files are transferred over a WAN.
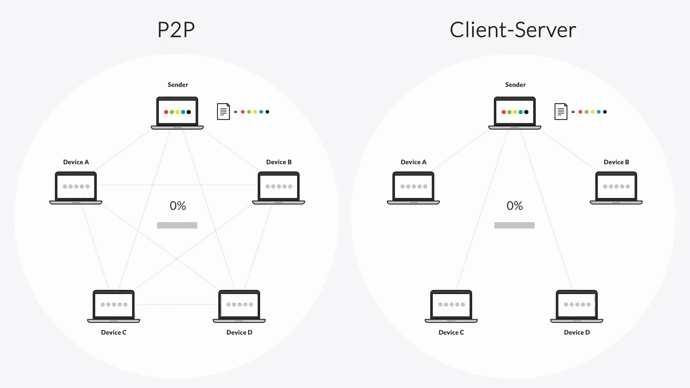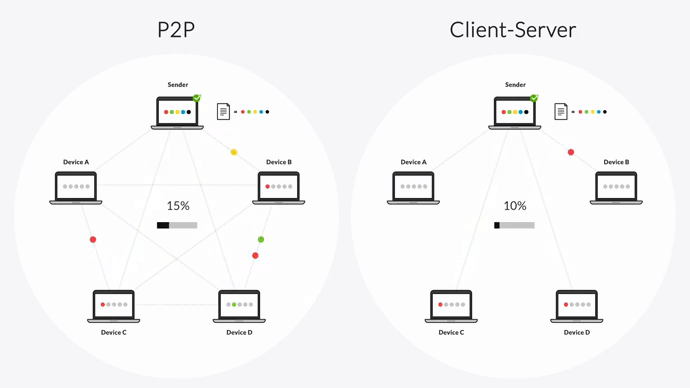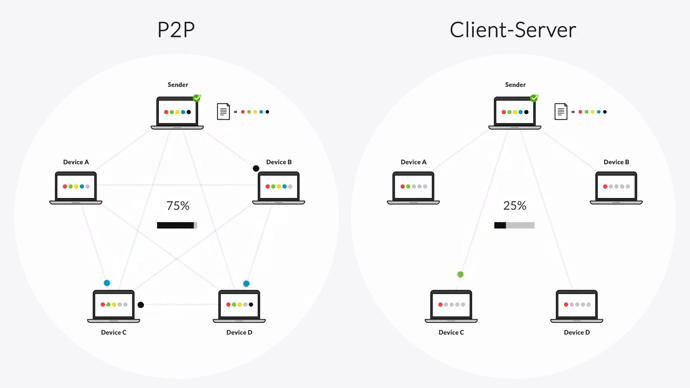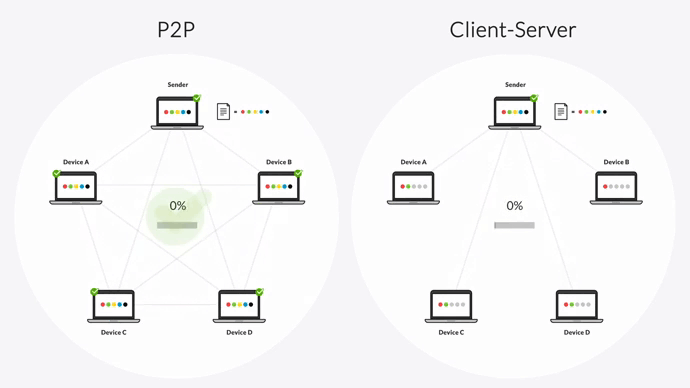
In a client-server transfer architecture, there is one sender (the hub server) and one receiver (the destination server). This means replication can only occur to one destination at a time — the hub server can’t transfer files to a second device until transfer is complete on the first. This can create a backlog of file transfers, especially when transferring large files or large numbers of files.
Resilio uses a peer-to-peer (P2P) transfer architecture. Every device in the replication network can send and receive data from every other device. And when transferring data among several devices, each device can also become a sender. In other words, once Device A receives a file packet, it can begin sharing that packet with other devices in the network — resulting in transfer speeds that are 3-10x faster than DFSR or any other client-server solution.
DFSR’s slow transfer architecture is made worse by the fact that it relies on TCP/IP transfer protocol. TCP/IP suffers from two issues that make it perform poorly over WANs:
a) How it responds to packet loss
Due to its use of TCP/IP (and other reasons), DFSR always assumes packet loss is due to channel congestion, and reduces transfer speed in order to reduce the load on the network.
But packet loss on WAN networks can occur for other reasons, such as a failure on the intermediate device. Reducing transfer speed doesn’t reduce packet loss and only results in greater delays (i.e., your backlog builds up).
b) How it ensures data delivery
TCP/IP ensures data gets delivered to its destination using confirmation packets. In other words, the sender sends a packet to a receiver, and the receiver returns a confirmation packet acknowledging receipt. Retransmission time (RTT) is the time it takes a packet to travel from sender to receiver or vice versa.
The RTT on a LAN (local area network) can be as little as .01 ms. But on a WAN, RTT can be 800ms or more. So using TCP/IP over a WAN can significantly reduce transfer speed by up to 2 seconds for each new packet transfer.
While Resilio can use TCP/IP over LANs, it uses our proprietary transfer protocol — Zero Gravity Transfer (ZGT ™) — on WANs.
ZGT ™ optimizes WAN transfer using:
- Bulk transfer: By sending packets periodically with a fixed packet delay, ZGT creates a uniform packet distribution in time.
- Congestion control: ZGT calculates the ideal send rate using a congestion control algorithm.
- Interval acknowledgement: Rather than sending confirmation for each individual packet, ZGT sends confirmation for a group of packets that provides additional information about lost packets.
- Delayed retransmission: To decrease unnecessary retransmissions, ZGT retransmits lost packets once per RTT.
2. DFSR Scales Poorly
As your enterprise organization and replication environment grow, DFSR’s performance will suffer when faced with:
a) Large files and large numbers of files
DFSR is notoriously bad at transferring large files and large numbers of files. This is not only due to the fact that it uses a 1 to 1 client-server transfer architecture, but also because:
- To replicate files, DFSR must scan through the entire file/folder in order to detect and transfer file changes. Doing so takes a long time, especially for large replication jobs.
- DFSR uses remote differential compression to detect and replicate file changes. RDC takes a long time to calculate file changes, causing large replication jobs to take even longer.
b) Lots of activity
For those same reasons, DFSR also performs poorly when there’s lots of activity — i.e., many/frequent file changes that need to be replicated. Every time you make a change to a file, the slow process of scanning folders and detecting changes has to begin again. The more changes you make, the bigger your DFSR backlog queue grows.
c) Replicating to more servers
The more servers you add to your replication environment, the worse DFSR will perform.
DFSR’s 1 to 1 replication approach means that replication must complete to one server before it can begin on another server. This issue is compounded if one server is far away or on a slow network, as it forces all the other servers to wait until the slow transfer is complete.
DFSR also uses static IP: ports to establish connections to different machines. If a machine’s IP: port changes (or isn’t available), DFSR stops working and must be reconfigured by a human.
DFSR’s inability to adequately synchronize files to multiple destinations is one of the most common causes of a large backlog queue. Since most organizations sync files across multiple servers in multiple locations, using DFSR quickly becomes impractical.
Resilio provides fast replication at scale using:
Optimized checksum calculations
A checksum is an identification marker for a file. When a file gets changed, the checksum also changes. Resilio uses optimized checksum calculations (as well as notifications from the host OS) to quickly detect file changes and replicate only the changed parts of a file — which reduces network load and increases transfer speed.
In the event of a network failure mid-transfer, Resilio can perform a checksum restart in order to resume transfer where it left off. When file transfers are interrupted on DFSR, it must start again at the beginning.
File chunking and omnidirectional file transfer
With its P2P transfer architecture, Resilio can quickly replicate large files and large numbers of files across your entire replication environment.
Resilio Platform uses a process known as file chunking — transferring files in chunks. Once a server receives a file chunk, it can immediately share it with any other server in your network.
For example, Server 1 begins replicating file changes to Server 2. Server 2 can share that chunk with other servers as soon as it is received. Sync speed is significantly increased because:
- Multiple servers are sharing data simultaneously.
- Servers can receive transfers from the server closest to them.
- Transfer is spread out across multiple servers, reducing the load on any single network.
This also means that Resilio is organically scalable. Since every device can share data with every other device in your network concurrently, adding more devices enhances performance — i.e. increases transfer speed and reduces the network load across your environment. On average, Resilio increases performance over conventional approaches by 10-20x, depending on the use case (such as number of files, network latency, bandwidth, storage capabilities, etc.).
For example, in the Resilio model, you can sync files between 2 devices in about the same time as it takes to sync files between 200 devices, with available network capacity. By contrast, in a traditional “point to point” or “client server” model, the maximum number of devices that can concurrently be synchronized is 2.
And Resilio Platform is a cross-platform solution. In addition to Windows servers, Resilio runs on Linux, macOS Server, BSD, and a variety of NAS-specific operating systems (Synology, TrueNAS, etc.).
The IT manager at an employee benefit company said:
“We went from spending at least 2 hours per night dealing with replication and troubleshooting issues with DFSR to spending about 1 hour per week monitoring jobs using Resilio.”
Read more about how Resilio helped them achieve reliable and predictable replication.
3. DFSR can’t provide Active-Active High Availability
Many organizations require Active-Active High Availability. Active-Active HA refers to an environment where two different sites are actively serving users and both are available for redirection in case one goes down — which is useful for balancing network load (for unreliable network connections and VDI scenarios), quickly and accurately recovering data in disaster recovery scenarios, and quickly replicating concurrent data changes.
If you need Active-Active HA, DFSR is not a good option because it:
- Is unreliable: DFSR often queues up changes in the backlog without fully replicating files (or replicating them at all). It also may not keep all sites synchronized. If there’s a failure on one site, you could lose the files that were not replicated.
- Scales poorly: DFSR often fails when forced to replicate many concurrent changes simultaneously, such as log-off storms. For example, if 1000 users log off at the same time, this can create thousands of file changes that need to propagate immediately. This can overwhelm DFSR, causing it to crash or corrupt data.
On the other hand, Resilio Active Everywhere’s bidirectional and omnidirectional synchronization makes it a perfect solution for Active-Active HA. If one site goes down, any client or group of clients can provide the service, each operating as nodes on the network. And file chunks get distributed across multiple endpoints concurrently. Not only does this balance the load between servers, it provides those in VDI scenarios more bandwidth and the ability to replicate file changes any time, anywhere.
According to the IT manager responsible for DFS replication at a Fortune 500 engineering and construction firm,
“There was simply no way to achieve true active-active high availability (HA) across sites, prior to Resilio. “We went from a 30-minute replication window using Microsoft DFSR to a 5-minute lead time to have all data synchronized across all sites with Resilio,” they said.
Read more about it here.
And with WAN optimization, Resilio ensures data transfer occurs as quickly as possible over any network. Users access the servers closest to them, and Resilio dynamically routes around failures and network latency.
Use Resilio for Worry-Free File Replication
DFSR is a suitable replication tool for small environments with a few files. While we hope the DFSR solutions we compiled work for you, DFSR is highly problematic and you’ll eventually need a more reliable replication solution.
If you want faster, reliable, scalable, and highly-available replication that always works, schedule a demo with our team today.





