


Rsync is an open-source, command-line file replication solution that can be extremely slow when replicating a large amount of data. A quick Google search for “Rsync large number of files” will return multitudes of forums and articles from Rsync users who are having trouble replicating their large file directories in an acceptable time frame.
Rsync works best when network conditions are good (i.e., low-latency and minimal packet loss) and when performing simple replication jobs, such as syncing small files between two offices, distributing a small number files from one endpoint to one or several other endpoints, or consolidating data from one or several endpoints into a single endpoint.
However, it’s not a great solution for synchronizing large files or larger file systems containing 100K+ files, complex synchronization scenarios requiring multi-directional sync, and transfer over WANs (wide area networks) or unreliable networks with long retransmission times and varying degrees of packet loss. In these scenarios, Rsync’s performance falters due to its rudimentary technology, how it detects file changes, and how it transfers files. Rsync can only sync files in one direction.
There are a few solutions you can try to increase sync speed for a large number of files. We’ll share several in this article and link to forums where you can find more answers.
But ultimately, you may need to confront the primary issue with Rsync: It’s an aging technology that was built in and designed for a time when files were smaller and replication jobs were small and simple. As your replication environment grows (i.e., replicating large files, replicating larger numbers of files, and replicating to many endpoints), you’ll need to find a better file replication solution that can handle your needs.
Resilio Active Everywhere (formerly Resilio Connect) is a server replication solution that can handle the synchronization, distribution, and consolidation tasks that Rsync (and other solutions) can’t. Active Everywhere uses a P2P (peer-to-peer) transfer architecture and WAN optimization to easily replicate files of any size or number over any network. Resilio offers one-to-one, one-to-many, and n-way sync so that you can replicate files on any number of devices — in any direction.
Resilio’s Management Console makes it easy to manage replication across your entire environment and spot and fix any issues that arise. For example, Active Everywhere is used by organizations in gaming, tech, media, marine, retail, and logistics, among other organizations, to quickly and reliably replicate files and enhance business workflows.
In this article, we’ll discuss:
- How to get insight into Rsync replication status
- The 5 reasons why Rsync performs poorly on larger synchronization jobs
- 6 ways to speed upRsync when syncing a large number of files
- How Resilio Platform overcomes the challenges that hinder Rsync and provides a superior synchronization solution for large replication jobs.
If you want to use Resilio to enhance speed on large replication jobs, you can get set up and begin replicating in as little as 2 hours by scheduling a demo with our team.
First, Check Rsync Replication Status
One of the biggest issues with free replication solutions (like DFSR, Rsync, robocopy, etc.) is the lack of visibility, diagnosability, and insight into the state of replication in your environment. This makes it difficult to identify, diagnose, and address issues. And it creates stress for IT admins who rely on Rsync to distribute, consolidate, or synchronize files for business applications.
But there are a few Rsync commands you can use to check your replication status. Doing so may help you narrow down the potential causes of your problem so you don’t waste time trying erroneous solutions.
1. Check the progress of a specific transfer
To check on the progress of your replication job, use the command:
--progress OR -PYou can enter the name of the source and remote servers to check on the progress of a specific transfer:
rsync -av --progress [Source Server] nixcraft@[Remote Server]~The command should produce an output similar to this:

2. Check the progress of your entire replication job
To see statistics on the entire replication job rather than individual file transfers, use the following command:
--info=progress23. Monitor the progress of data through a pipeline
To monitor the progress of data through a pipe, use the pv command:
rsync -vrltD --stats --human-readable [Server 1] [Server 2] -lep -s 42This command returns the following info:
- Time elapsed
- ETA
- Current throughput rate
- Percentage completed (with progress bar)
- Total data transferred
5 Causes of Poor Rsync Performance
Rsync is a Linux-based tool that was invented back in the 1990’s when file sizes and systems were small. As such, it’s an aging technology that doesn’t perform well in larger, modern replication environments.
As your replication environment grows (i.e., replicating large files, replicating a large amount of files, or replicating to many endpoints), Rsync will take longer to replicate, break down, and create a bottleneck in your workflow. To understand why this happens, how to enhance Rsync replication, and when it’s time to seek a new synchronization solution, you need to understand the five sources of Rsync’s poor performance:
1. Rsync scans entire file systems for sync jobs
One of the ways Rsync enhances replication speed is through differential change detection at the file level. In other words, Rsync uses a differential sync engine to replicate only changed files (or changed portions of files).
But to accomplish this, Rsync must first scan the entire file system on both the source and target servers. It will then compare the file lists on the source directory with the destination files on the target directory to detect which files have been changed and determine which files to replicate.
Scanning the entire file system can take a long time. And as the size and quantity of the files in your replication environment grows, it will take even longer for Rsync to scan and sync them.
2. Rsync’s transfer protocol performs poorly over WANs
Rsync uses TCP/IP transfer protocol, which doesn’t transfer well over WANs and high-latency networks.
TCP/IP treats every acknowledgement delay and packet loss as network congestion and reduces transfer speed. While this approach helps certain applications share networks and balance the network load, in the case of WANs, delays and packet loss can occur often and aren’t indicative of network congestion. So, when transferring over a WAN, TCP/IP will reduce transfer speed and cause sync jobs to take longer.
On a separate but related note, Rsync offers no file encryption or other features to protect your data at rest or in-transfer (which is especially important when transferring over WANs). Your only security option is to use Rsync over SSH (Secure Shell protocol) to transfer or copy files.
3. Rsync operates on slow file transfer architectures
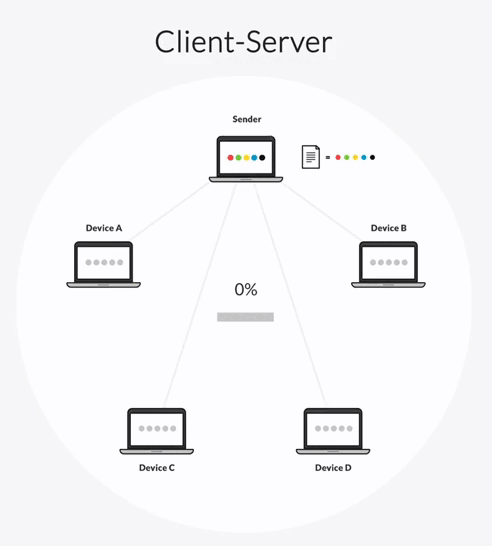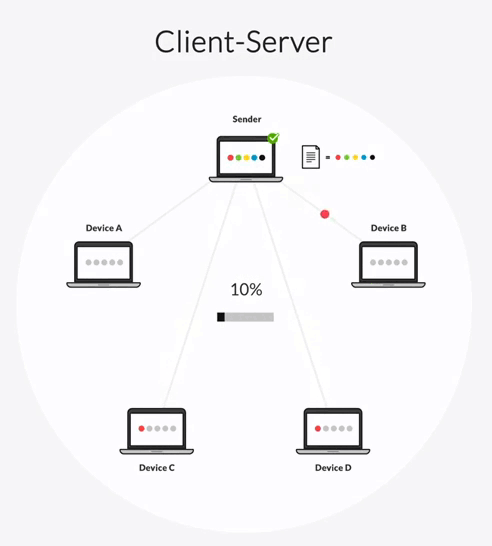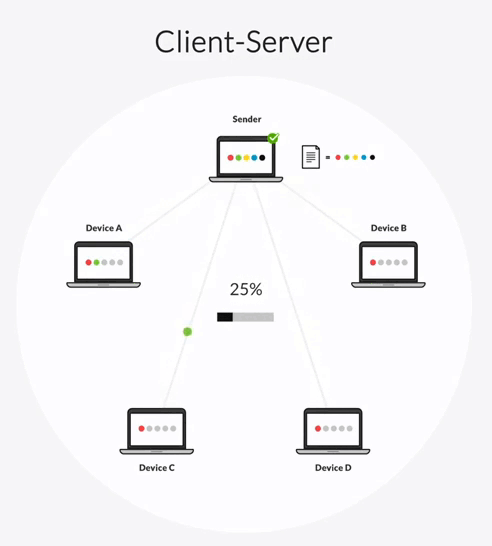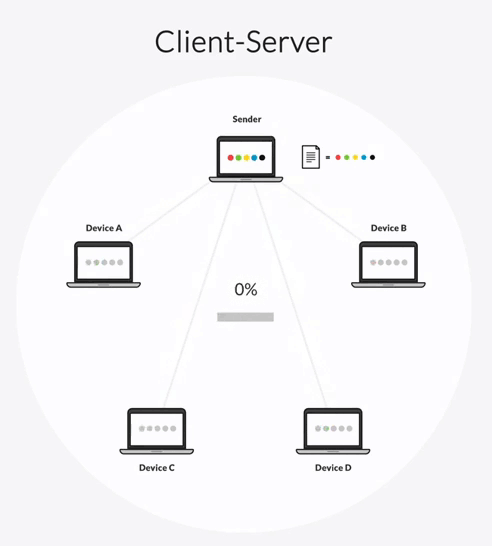
Rsync can be configured in one of two transfer architectures: client-server and “follow-the-sun.”
In a client-server architecture, one server is designated as a hub-server and all other servers are clients. The hub-server can transfer files to any client and receive files from any client. But clients can only transfer files to the hub-server, not to each other.
In this synchronization topology, the hub-server becomes a bottleneck in your transfer workflow. All file transfers must first go to the hub-server, which then replicates those files to every other client one-by-one. This creates two delays:
- The time it takes for a client to share file changes with the hub-server.
- The time it takes for the hub-server to share the changes with each client.
When running Rsync on a client-server topology, you can program it to perform parallel sync — i.e., replicating multiple files simultaneously rather than one at a time. However, parallel sync splits the network bandwidth between the different replication tasks. If your network is already slow, this can actually reduce replication speed even further.
The more clients in your environment (i.e. replication endpoints), the longer replication will take. The more files you’re replicating, the longer it will take for replication to complete for each individual client. And if one client is on a slow network and replication is delayed, every other client must wait for replication to complete before they can receive any files.
The other synchronization topology for Rsync is “follow-the-sun.” In this setup, replication occurs sequentially from one device to the next. For example:
- Server 1 will sync with Server 2.
- Once replication is completed between Servers 1 and 2, Server 2 will sync with Server 3.
- Server 3 will then sync with Server 4, and so forth.
Again, synchronization speed is impeded by the point-to-point nature of file transfer, the number of endpoints you’re replicating to, and the quality of the network connection on each device.
4. Rsync uses static IPs to establish connections
IP addresses are identifiers that allow devices to connect and share information with each other. Rsync’s system uses static IPs — i.e., IP addresses that always stay the same. But if the IP address on a server changes (which can occur because your ISP changes it or for various other reasons), Rsync can’t establish a connection and stops operating. Human intervention is required to fix the issue.
5. Rsync has poor scripting capabilities
There may be situations where you need your server replication solution to perform additional operations once synchronization is complete. For example, you may need to execute a software patch on all destinations, but only if all the devices have it.
Rsync can be wrapped in command line scripts and execute different operations after file transfer is complete. But Rsync’s scripting capabilities are limited. And programming operations becomes tricky when you need to synchronize script execution across multiple destinations (e.g., the software patch scenario mentioned above) and when you’re replicating cross-platform to machines with different OSs.
6 Ways to Increase Rsync Speed When Replicating a Large Number of Files
There’s no way for a well-meaning stranger to diagnose and fix your Rsync issues without any visibility into your replication jobs and environment. But based on how Rsync works and the common replication issues users have reported, we’ve put together a list of 8 solutions that may help speed up your sync jobs.
1. Update to the latest version of Rsync
Rsync updates their software periodically to improve performance. If you’re experiencing slow replication or other issues, check to ensure you have the latest version.
You can use the following guides to update Rsync:
- Update Rsync on Linux
- Update Rsync on Mac OS, Mojave, and High Sierra
2. Test the different transfer architectures
Experiment between the two Rsync transfer topologies — “follow-the-sun” and client-server — to see which works best for your replication jobs/environment.
Client-server enables you to run parallel sync instances. But doing so splits the network channel and increases the time it takes to complete a transfer to any single destination. This topology works best in environments with strong network connections, but won’t work well when transferring over WANs and networks with high-latency.
The “follow-the-sun” model performs file transfers one at a time. But that enables each transfer to utilize the full network bandwidth, and may result in faster sync.
3. Don’t use “–checksum”
Using the “–checksum” command programs Rsync to read every single block file when scanning the source server. Without it, Rsync will just read modification times and scan only the files that have been changed since the previous scan. While this creates a small potential for replication errors (i.e., failing to replicate some files that have been updated), it’s likely to produce faster file transfer.
4. Split files into multiple directories
Syncing a large number of files in a single directory will cause issues for Rsync. But if you split your files up into smaller directories or subdirectories, Rsync will have an easier time scanning file names and systems, comparing file changes, and replicating updates. On the downside, this creates some management complexity.
5. Transfer in small batches
You can potentially increase replication speed by using a script like Gigasync — an Rsync-based Perl script that performs incremental mirroring of enormous directory trees. Gigasync will divide up the replication workload by using Perl to recurse the directory tree and build smaller lists of files to transfer.
6. Check your RAM
When scanning files for replication, Rsync stores file information in memory. The amount of memory it uses is directly proportional to the number of files in a tree. In other words, a larger directory will use more RAM.
Slow replication may be due to a lack of RAM on your device(s). To see if this is the issue, perform a test replication while observing memory usage. For example, Linux uses left-over RAM as a disk cache. If RAM is low, there is less disk caching.
More potential solutions
For more potential methods for speeding up Rsync, check out the suggestions in these forums:
Use Resilio Platform for Superior Synchronization on Large Replication Jobs
Resilio Platform is a superior solution for file synchronization, distribution, scripting, and consolidation. It overcomes the challenges that hold Rsync back by:
- Using a P2P transfer architecture for faster sync speed and true real-time file transfer.
- Using WAN acceleration technology to enhance WAN transfer.
- Providing a high degree of flexibility and control over your replication jobs. Moreover, Resilio can be automated via scripting or APIs.
- Providing reliable, fault-tolerant replication.
- Using end-to-end encryption to provide secure file transfer.
- Move and sync files in any direction, in parallel: one-to-many, many-to-one, or many-to-many.
Fast, real-time replication with P2P file transfer
To start, both Resilio and Rsync use differential change detection to replicate only the changed portions of files. But while Rsync must scan all of the source files before every replication job — a process that eats up more and more time as the size and number of files increases — Resilio Platform uses real-time notification events from the host OS to detect and replicate changed files.
Resilio’s P2P-based file transfer architecture is also superior to both of Rsync’s replication topologies.
Unlike the client-server model, every device in a P2P environment is equally privileged and can share data with every other device. There’s no need to send changes to a hub-server first.
And unlike the “follow-the-sun” model, Resilio can transfer files across multiple devices concurrently.
When performing a replication job, Resilio splits each file into multiple blocks that transfer independently. Once a device receives a file block, it can begin sharing that block with any other device even before it receives the full file.
For example, imagine there are five servers in your replication environment, and Server 1 wants to share a large, single file with the other four servers. It can split that file up into six blocks and start sharing those blocks with Server 2. Once Server 2 receives the first file block, it can begin sharing it with Server 3 while awaiting the other five blocks. Once Server 3 receives the file block, it can share it with Server 4, and so forth.
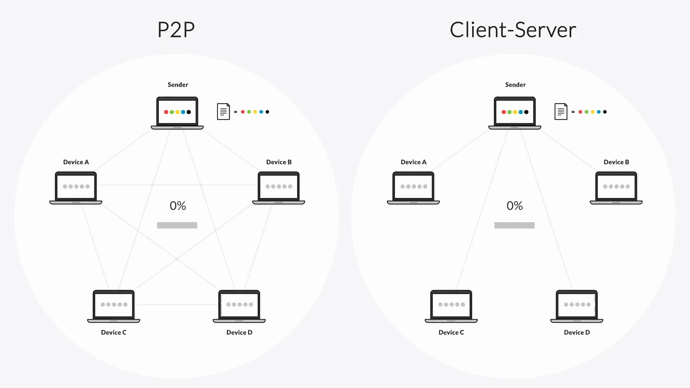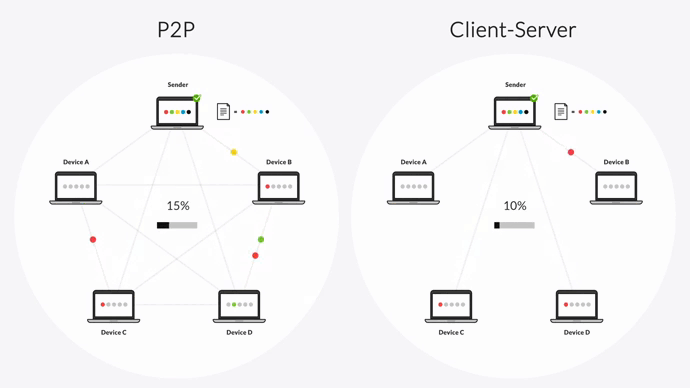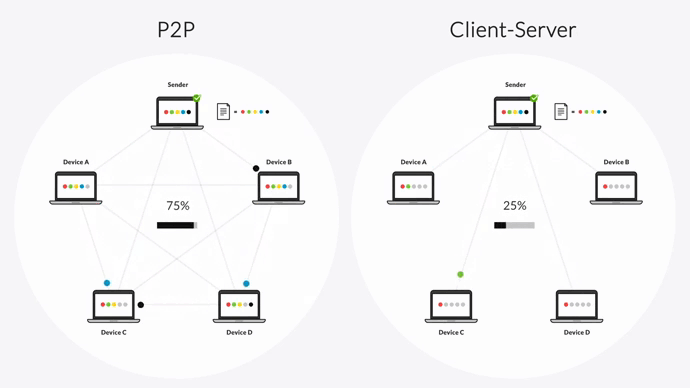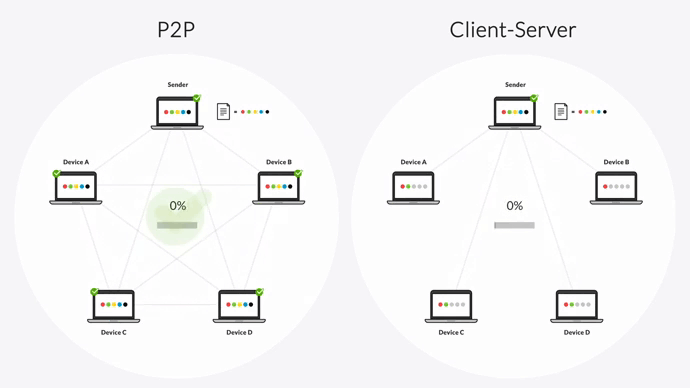
This replication methodology enables Resilio Platform to perform true multidirectional N-Way sync. And unlike Rsync’s version of parallel transfer (which splits up the network bandwidth), Resilio Platform can fully utilize the bandwidth across all devices and overcome any transfer bottlenecks over any distance and location — resulting in sync speeds up to 20x faster than Rsync.
After switching to Resilio Active Everywhere, the lead programmer at Larian Studios said: “For us, the main thing was fast transfer of data and obviously maintaining the integrity of all the data that we sync to our offices. And definitely the cost is very important. We were happy to find a solution where we could use our in-place architecture to keep down the cost.”
WAN acceleration for superior WAN transfer
As stated earlier, Rsync uses TCP/IP transfer protocol for all transfer jobs. But TCP/IP isn’t optimized for WAN transfer and can potentially reduce sync speed.
While Resilio uses TCP/IP for LAN transfer, it uses a proprietary WAN acceleration transfer protocol known as Zero Gravity Transport™ (ZGT) to optimize transfer over WANs. ZGT minimizes packet loss and latency while maximizing transfer speed by using:
- A bulk data transfer approach: To create a uniform packet distribution over time, ZGT periodically sends packets with a fixed packet delay.
- Interval acknowledgements and delayed retransmission: With ZGT, the destination device doesn’t send acknowledgements every time it receives a data packet. Instead, it sends interval acknowledgements for a group of packets that includes information about lost packets. Resilio then retransmits lost packets once per RTT, which decreases needless retransmissions and improves speed.
- A congestion control algorithm: ZGT uses a congestion control algorithm that calculates the ideal send rate by periodically probing the RTT (Round Trip Time).

Further reading: For more information on how Resilio optimizes WAN transfer, check out our WAN optimization whitepaper.
More flexibility and control over your replication environment
Resilio Platform is one of the most flexible server synchronization solutions available. It’s an agent-based solution that can perform file distribution, consolidation, scripting, and synchronization. Resilio Agents can be installed on Windows, MacOS, Linux, FreeBSD, Android, Ubuntu, Unix, and popular virtualization platforms, servers, storage, NAS devices, networks, and cloud storage services providers.
Each server can support up to 10K endpoints, be they devices, cloud storage buckets, desktops, or servers running a Resilio agent. Resilio’s Management Console can be clustered to support a massive number of endpoints. For example, one Resilio user has more than 100K endpoints in their edge computing deployment.
You can manage and monitor all replication jobs and functions using Resilio’s Management Console — a centralized, web-based system with an easy-to-administer graphical user interface. Resilio’s dashboard provides real-time notifications and detailed logs that keep you informed about the state of replication in your environment.
You can use Resilio’s powerful REST API to automate and configure key replication parameters, such as:
- Bandwidth use: You can adjust bandwidthpermissions, controlling the amount of bandwidth each device uses. You can also create schedules that control bandwidth usage based on the time of the day or day of the week.
- Network and storage stack: You can adjust parameters in your network stack, such as packet size, buffer size, and more. And you can control aspects of your storage stack by controlling file priorities, data hashing, and more.
- Functionality: You can manage agents, script complex functionality, create replication groups, or report on data transfers in real-time.

By configuring Resilio’s performance to suit your needs, you can control costs, manage resource usage, and easily spot and fix problems.
Reliable, fault-tolerant replication
Resilio Platform provides reliable replication in any environment and on any network.
Because it uses P2P transfer, Resilio doesn’t have any single point of failure. If one device goes down, files and services can be provided by any other device in your network. And Resilio can dynamically route around network failures to quickly get data or services from any device in your network. And, in the event that a network goes down in the middle of a file transfer, Resilio can perform a checksum restart to resume the file transfer where it left off (unlike Rsync, which restarts the transfer over again).
Unlike Rsync, Resilio Platform uses dynamic IPs that require no human intervention. Devices with Resilio Agents use trackers or multicast to discover the addresses of any device they need to exchange data with.
Secure file transfer with end-to-end encryption
Rsync lacks any encryption features. Using Rsync without an additional encryption solution (such as SSH or a VPN) leaves your data susceptible to hacking.
But Resilio Active Everywhere’s state-of-the-art data security was reviewed and verified by 3rd party security experts. It enables you to securely transfer files over encrypted connections using:
- In-transit encryption: Resilio encrypts files in transit using AES 256.
- Forward secrecy: Resilio protects sensitive data using one-time session encryption keys.
- Cryptographic data integrity validation: Using an integrity validation process, Resilio ensures that data arrives at its destination intact and uncorrupted.
- Mutual authentication: Resilio only delivers files to designated endpoints.
If you want to use Resilio to enhance speed on large replication jobs, you can get set up and begin replicating in as little as 2 hours by scheduling a demo with our team.



